

Agentic AI
,
Artificial Intelligence & Machine Learning
,
Next-Generation Technologies & Secure Development
New Study Shows AI Agents Can’t Work Without Humans in the Loop, But Give Them Time

Artificial intelligence agents are quickly moving from experimental demos to enterprise pilots. Ultimately agents will be embedded in core business processes, and they’re already being used by professionals for tasks such as financial analysis, document review and drafting. But as agentic AI gains momentum, one question goes largely unanswered: How can we measure the effectiveness of AI agents?
See Also: On-Demand | NYDFS MFA Compliance: Real-World Solutions for Financial Institutions
A recent benchmark study, the AI Productivity Index for Agents, or APEX-Agents, sought to answers questions on the minds of CIOs and COOs everywhere. The research, based on real tasks designed by investment banking analysts, management consultants and corporate lawyers, evaluated whether AI agents can handle long-term, cross-application tasks common in knowledge-intensive industries.
How did the agents perform? Not too well. AI agents succeeded on their first try just 24% of the time, based on the Pass metrics for execution of machine code. While AI agents aren’t useless tools, it does call for a reassessment of how they can be used more effectively.
So, what does that 24% success rate really mean, and what types of enterprise work are AI agents actually ready to handle today? Let’s break down the report.
Putting AI Agents to the Test
The productivity index covers 480 tasks across 33 detailed project environments, referred to as “worlds” in investment banking, management consulting and corporate law. Each world has about 166 files and provides access to workplace tools such as documents, spreadsheets, presentations, PDFs, email, calendars and code execution.
Mercor, an AI-driven recruitment firm, surveyed 227 experts to understand their daily work to help create scenarios and tasks in the APEX-Agents study. Participants include 58 financial and investment analysts, 77 management consultants and 92 lawyers, with an average of 10.8 years of experience. A typical task takes a skilled worker between one and two hours, and the benchmark study sought to assess whether AI agents can perform at the level of junior and mid-level professionals.
“We set out to find whether today’s AI agents perform economically valuable tasks,” said Mercor CEO Brandon Foody. “Are they ready to work with teams, in real software tools and deliver client-ready work? We found that even the very best models struggle with complex real-world tasks, failing to meet the production bar.”
How Good Is Good Enough?
The leading model used in the test had a Pass@1 score of 24%, indicating it met all task requirements roughly once in every four attempts. The second-best model scored 23%, and the rest scored between 18% and 20%. Surprisingly, open-source models perform significantly lower, with scores below 5%.
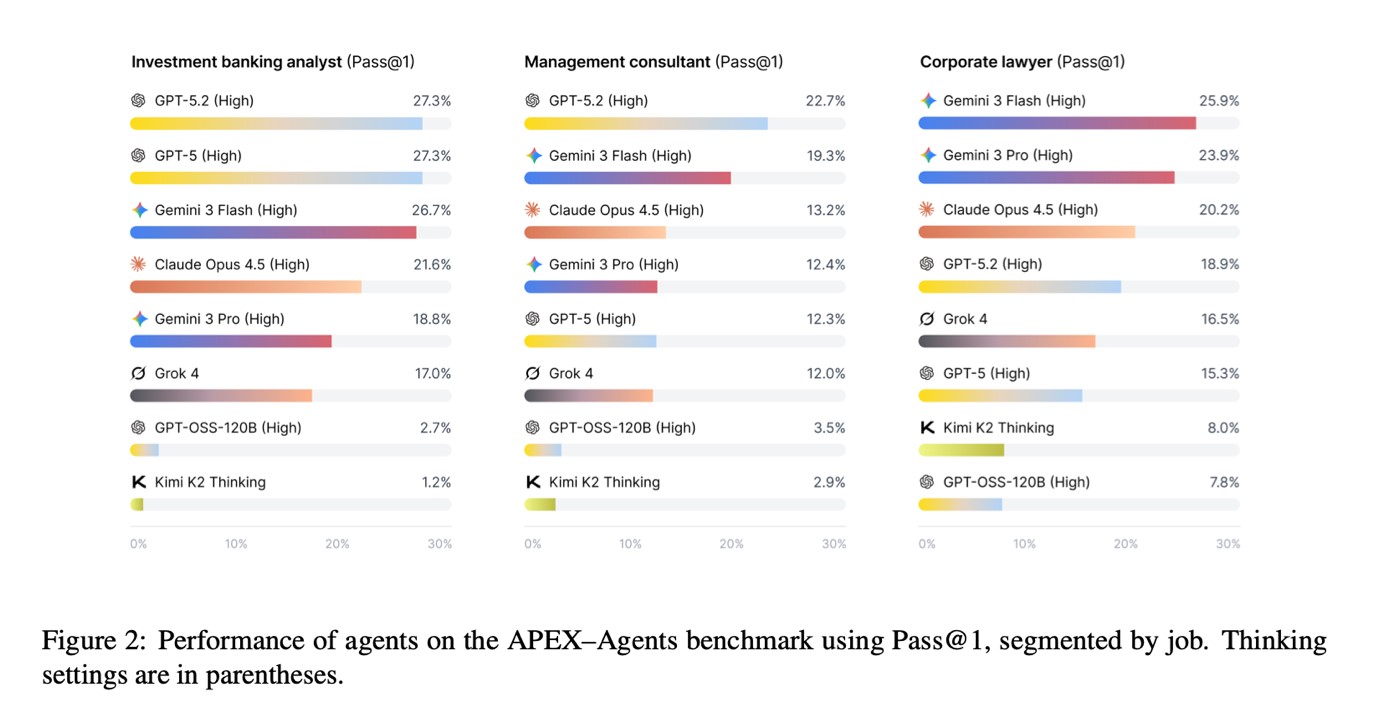
It looks like failure across the board. But the Pass@1 standard is designed to be stringent. Tasks are evaluated with clear, strict rules and missing even one key part counts as a failure. It reflects the reality of working with clients, where partial correctness is unacceptable.
But when AI agents were allowed multiple attempts, performance improved. With eight runs per task, the best agents succeeded at least once about 36% to 40% of the time. This gap reveals something important. The capability exists, but execution is faulty.
Consistency remains the key challenge for agents. When tested on parameters that demand success across all eight runs, performance declined significantly, with the top model achieving only 13.4%. This fluctuation affects real-world deployment, suggesting that AI agents are not yet sufficiently reliable to perform consistently without supervision.
One of the most revealing discoveries in APEX–Agents is understanding what happens when agents fail. Failure doesn’t necessarily mean the model is useless. In different models, even unsuccessful attempts earn partial credit. It shows that agents often accomplish significant parts of the task even if they miss some criteria.
This is reflected in the mean task scores, which approximate 40% for the best agents. This means agents do produce acceptable deliverables.
For AI practitioners, this changes how productivity is viewed. Even if agents can’t handle a task entirely on their own, they can still reduce human effort, speed up processes, and free up time for validation and judgment.
Agents Struggle Mostly in Execution
The major issue facing agents doesn’t have anything to do with domain knowledge or reasoning. Most failures pertain to execution and orchestration. For example, agents often exceeded the benchmark’s 250-step limit, indicating inefficient planning or looping. They struggled with tasks that require creating or editing files rather than returning text, and they made excessive tool calls without converging on a solution.
Researchers found that the most resource-heavy agent, which used the more tokens and steps, also experienced more timeouts. The data shows that increased computation doesn’t always lead to better results. Successful executions typically involve fewer steps, which calls for disciplined use.
This distinction is particularly important for enterprise applications. The real bottleneck relates to navigating real systems and artifacts over extended workflows.
What Are Agents Ready to Do?
The findings indicate most AI agents today are suitable for focused, well-defined parts of professional tasks rather than managing entire tasks independently, performing comparatively well at:
- Data extraction and transformation;
- Initial analysis and summaries;
- Updating existing models or documents under clear instructions;
- Exploring multiple solution paths with retries.
But agents struggle with:
- Delivering outputs without supervision;
- Maintaining consistency across long, multi-step workflows;
- Reliably manipulating files without anomalies.
This means early adopters can currently use agents more effectively as tools integrated into human-led workflows, rather than in fully autonomous processes.
Redefining Productivity
Does this mean AI agents are overhyped? It certainly shows that vendors’ productivity claims need better measurement. A 24% success rate doesn’t mean agents are failing. It means they’re operating probabilistically, and enterprises need to find ways to work around that limitation.
The benchmark also shows agents can effectively assist with complex tasks, but only when their limitations are recognized and addressed through careful task structuring. While productivity improvements are possible, they are inconsistent and depend on specific conditions.
The key takeaway for technology leaders is AI agents aren’t ready to work without humans in the loop, but if you go in with the right expectations and the patience to fine-tune the execution, your agentic AI deployment will eventually get better at completing the task.